LORA(低秩自适应)
LoRA 允许我们通过优化适应过程中密集层变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。
LoRA 的思想很简单:
在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。训练的时候固定 PLM 的参数,只训练降维矩阵A 与升维矩阵B 。而模型的输入输出维度不变,输出时将BA与 PLM 的参数叠加。矩阵A用随机高斯分布初始化 ,矩阵B用 0 矩阵初始化 ,保证训练的开始此旁路矩阵依然是 0 矩阵。
优势:
- 参数量较全参数微调(Fine-Tuning)显著降低,参数量和现有高效参数微调方法持平或更低。
- 性能优于其它参数高效微调方法,和全参数微调(Fine-Tuning)基本持平甚至更高。
目前 LORA 已经被 HuggingFace 集成在了 PEFT(Parameter-Efficient Fine-Tuning) 代码库里。
Adapte Tuning
如下图所示的 Adapter 结构,将其嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将 Adapter 设计为这样的结构:
首先是一个 down-project 层将高维度特征映射到低维特征
然后过一个非线形层之后,再用一个 up-project 结构将低维特征映射回原来的高维特征
同时也设计了 skip-connection 结构,确保了在最差的情况下能够退化为identity(类似残差结构)。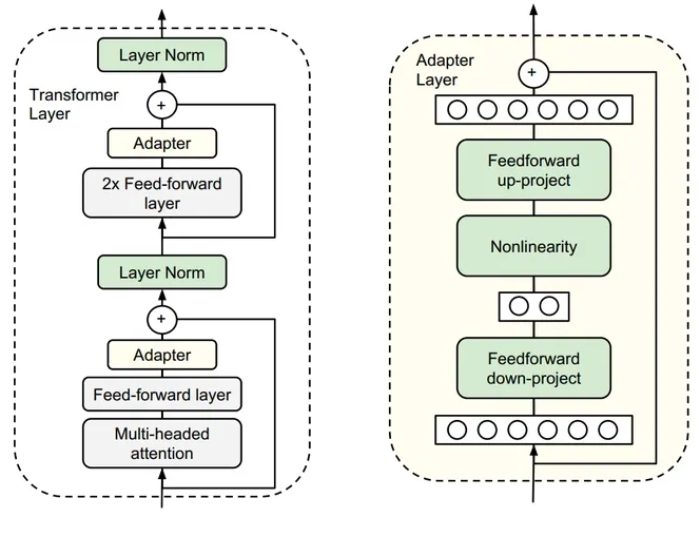
Prefix Tuning
与Full-finetuning 更新所有参数的方式不同,该方法是在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。该方法其实和构造 Prompt 类似,只是 Prompt 是人为构造的“显式”的提示,并且无法更新参数,而Prefix 则是可以学习的“隐式”的提示。同时,为了防止直接更新 Prefix 的参数导致训练不稳定的情况,他们在 Prefix 层前面加了 MLP 结构(相当于将Prefix 分解为更小维度的 Input 与 MLP 的组合后输出的结果),训练完成后,只保留 Prefix 的参数。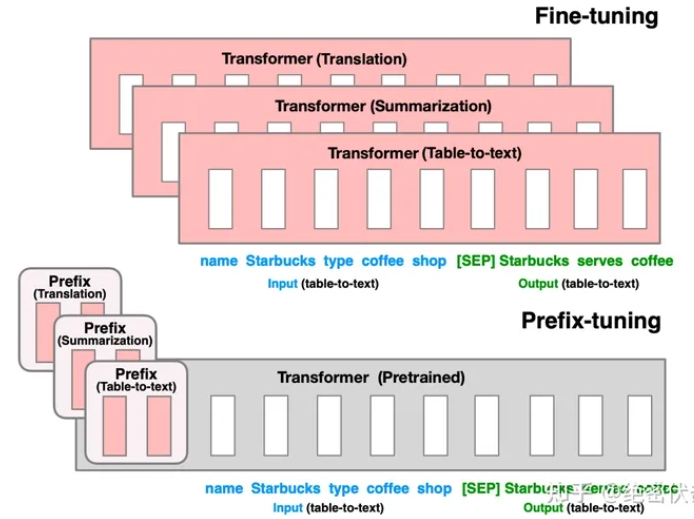
Prompt Tuning
该方法可以看作是 Prefix Tuning 的简化版本,只在输入层加入 prompt tokens,并不需要加入 MLP 进行调整来解决难训练的问题,主要在 T5 预训练模型上做实验。似乎只要预训练模型足够强大,其他的一切都不是问题,随着预训练模型参数量的增加,Prompt Tuning的方法会逼近 Fine-tune 的结果。固定预训练参数,为每一个任务额外添加一个或多个 embedding,之后拼接 query 正常输入 LLM,并只训练这些 embedding。左图为单任务全参数微调,右图为 Prompt tuning。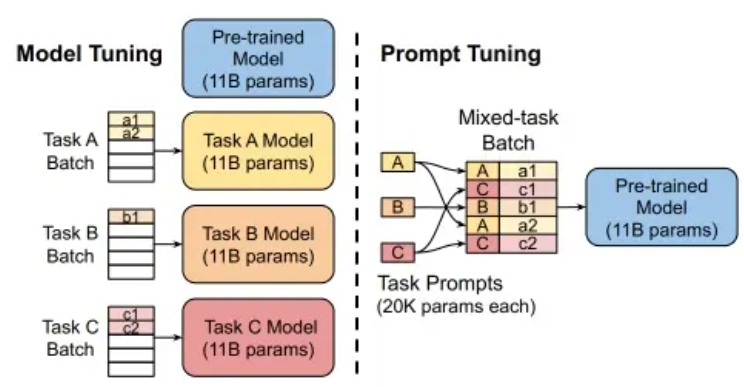
P-Tuning v1
P-tuning 依然是固定 LLM 参数,利用多层感知机和 LSTM 对 Prompt 进行编码,编码之后与其他向量进行拼接之后正常输入 LLM。
P-Tuning v2
P-Tuning v2 的目标就是要让 Prompt Tuning 能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌 Fine-tuning 的结果
相比 Prompt Tuning 和 P-tuning 的方法, P-tuning v2 方法在多层加入了 Prompts tokens 作为输入,带来两个方面的好处:
- 带来更多可学习的参数(从 P-tuning 和 Prompt Tuning 的0.1%增加到0.1%-3%),同时也足够 parameter-efficient。
- 加入到更深层结构中的 Prompt 能给模型预测带来更直接的影响。

AdaLoRA
预训练语言模型中的不同权重参数对下游任务的贡献是不同的。因此需要更加智能地分配参数预算,以便在微调过程中更加高效地更新那些对模型性能贡献较大的参数。具体来说,通过奇异值分解将权重矩阵分解为增量矩阵,并根据新的重要性度量动态地调整每个增量矩阵中奇异值的大小。这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。
Supervised fine-tuning(SFT)
有监督微调,意味着使用有标签的数据来调整一个已预训练好的语言模型(LLM),使其更适应某一特定任务。通常LLM的预训练是无监督的,但微调过程往往是有监督的。当进行有监督微调时,模型权重会根据与真实标签的差异进行调整。通过这个微调过程,模型能够捕捉到标签数据中特定于某一任务的模式和特点。使得模型更加精确,更好地适应某一特定任务。
奖励模型的训练
在大语言模型完成 SFT 监督微调后,下一阶段是构建一个奖励模型来对问答对作出得分评价。奖励模型源于强化学习中的奖励函数,能对当前的状态刻画一个分数,来说明这个状态产生的价值有多少。在大语言模型微调中的奖励模型是对输入的问题和答案计算出一个分数。输入的答案与问题匹配度越高,则奖励模型输出的分数也越高。奖励模型(RM 模型)将 SFT 模型最后一层的 softmax 去掉,即最后一层不用 softmax,改成一个线性层。RM 模型的输入是问题和答案,输出是一个标量即分数。
参考文章:
https://zhuanlan.zhihu.com/p/623543497
https://zhuanlan.zhihu.com/p/627642632