数据并行(DP )
1、概念:
相同的模型分布在不同的GPU上,在不同的GPU上使用不同的数据。每一张GPU上有相同的参数,在训练的时候每一个GPU训练不同的数据,相当于增大了训练时候的batch_size。数据并行基于一个假设:所有节点都可以放下整个模型。这个假设在某些模型上(如GPT3)是不合理的,因此我们还需要模型并行。
2、并行方式:
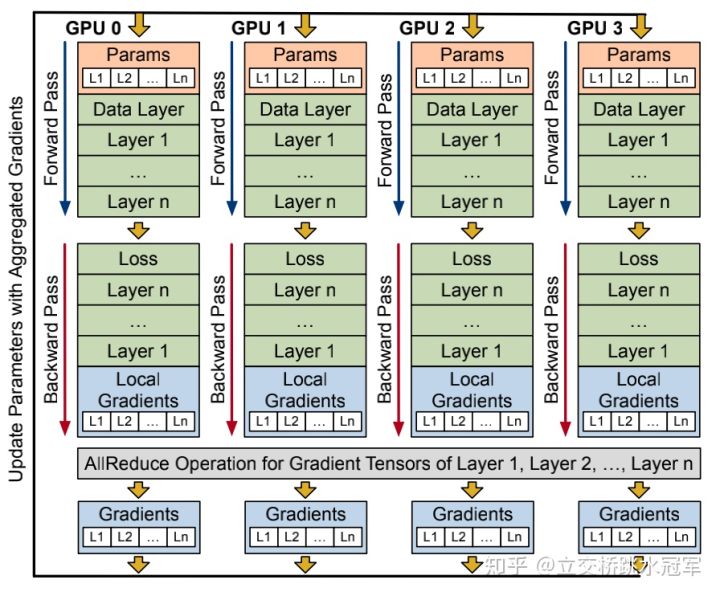
2.1 同步训练:每个前向、反向结束后显示同步(把每一个GPU上的梯度进行汇总,再在GPU上进行相同的参数更新。)
实现简单,适合同构场景;一个节点出现故障会影响整体计算性能;
传统中心化PS(Parameter Server)方式的同步训练:存在性能瓶颈(PS需要和很多的不同的节点进行通信,当集群的节点数增加的时候,会存在性能瓶颈);
All-Reduce方式的同步训练:目前最广泛采用,几乎所有框架都支持(各个GPU反向传播计算完梯度之后,通过一种像round all reduce环形结构,直接将参数更新);
显示训练,在All-Reduce时时没法进行下一步训练的。
2.2 异步训练:只进行部分同步或不显示同步。
适合异步训练,可能导致潜在的收敛性问题;
节点和PS通信,将梯度传给Sever的时候,Sever直接用参数进行更新,从Sever拿到更新后的参数进行下一步训练。当有的节点训练快,而有的节点训练慢,训练快的节点训练好后等一会就不等了,快的节点之间做一次通信后接着下一轮计算,慢的节点什么时候算好了再和其他节点一起all reduce梯度。这样可能将梯度发送给PS的时候,从PS拿到的参数是更新了好几个版本之后的,每个节点梯度不一样,根据不同的参数算得的梯度再去做all reduce就有一些不合理,就会导致神经网络精度受损。
传统异步方法:ASGD等;
其他:把其中部分的计算节点组成一个组,每次在这个组之内进行梯度的汇总和更新。
模型并行(MP )
1、概念:将模型切分到不同的GPU上,将模型的参数分到不同的GPU上,每一个GPU上的参数量大大减小,这样可以容纳更大的模型进行训练。参考下图,4个节点运行一个模型,4个节点(machine)将5层的网络做了切分
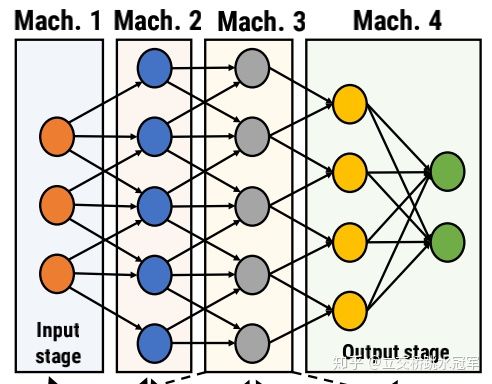
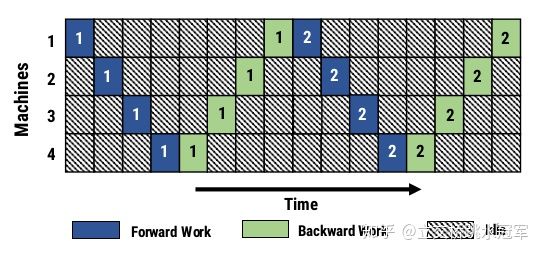
切分完之后,跑网络的方式也很简单:把输入先扔给Mach. 1,Mach.1 算完把它得到的结果扔给Mach. 2。就这样一直扔到Mach.4,Mach.4开始做反向传播,一直传播到Mach.1,这就是完整的一个iteration。上面图片中深蓝色表示Forward计算,绿色表示Backward计算,数字代表iteration的序号
流水线并行(PP)
1、概念:基于模型并行,一个batch结束前开始下一个batch,以充分利用计算资源。将模型按层进行切分,将不同的层放入不同的GPU,训练的时候数据像流水一样在GPU上进行流动。
对于模型并行,在任何时刻也没有两个节点在同时工作,根本就没有并行:大部分时间的大部分节点都是无所事事的状态,为了减少浪费,我们引入了Pipeline的概念:如果我们同时进行多个iteration,每个节点在同一时刻负责不同的iteration的计算,就可以避免数据依赖,不用在原地干等了,如下图所示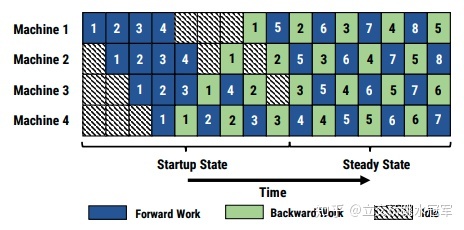
不过这种做法会产生新的问题:在普通情况下,我们算第二个iteration的情况下需要用第一个iteration后更新的模型来算,但是如上所示,对于Machine 1,我第二轮开始跑(深蓝色的2格子)的时候,第一轮(浅绿色的1格子)还没更新完。
PipeDream是一套融合了流水线(Pipeline),模型并行(model-parallism)以及 数据并行(data parallelism)三个机制的高效模型训练方案。在图像模型上测试可以达到1.45至6.76的加速比。PipeDream核心在于解决两个问题:(1) 对于一个给定的模型与分布式系统,如何划分任务(即哪个节点负责哪些layer,某些layer是数据并行还是模型并行)(2)对于流水线模型,如何避免流水线本身带来的训练的问题。
PipeDream就是一个将Data Parallel与Pipeline结合在一起的框架,如下所示,将一个5层的网络均匀的分配到8个节点来运算,尽可能提升系统的性能
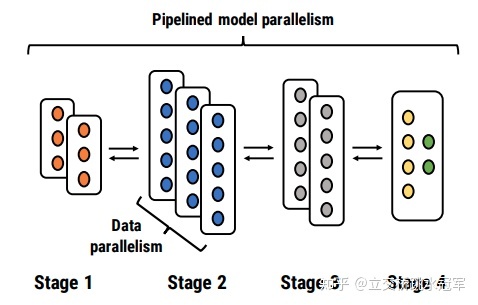
流水线模型可以认为是一个动态规划模型:把M层的网络分给N个节点算,最短的时间要么是M-1层分给N-1个节点算,或者M-1层分给N-2个节点算。当然因为是流水线,所以我们最关注output through,就是吞吐量,取决于流水线最长的一个节点的时间
2、切分方式:按层切分(流水线并行)、层内切分(模型并行)。
四、混合并行(HP)
混合使用上述的两种或三种方法