Taint 使用说明
给节点增加taint
1 | kubectl taint nodes node1 key1=value1:NoSchedule |
设置节点不可调度并增加taint
1 | kubectl cordon node2 |
在节点上增加taint后(即增加污点后),k8s调度时对无法容忍这些污点的Pod,不会将这些Pod 调度到这些节点, 对于taint为effect: NoExecute的污点,会交由taint_manager进行处理,即NoExecuteTaintManager,节点上的所有Pod 都会被污点管理器(taint_manager.go)计划删除。而在节点被认定为不可用状态到删除节点上的 Pod 之间是有一段时间的,这段时间被称为容忍度,即tolerationSeconds
1 | tolerations: |
我们在创建Pod时,有时候并没有配置tolerations,此时k8s 会自动为Pod增加两个默认的toleration,TaintNodeNotReady,TaintNodeUnreachable,参考如下:
1 | var ( |
处理流程
NoExecuteTaintManager
处理节点node上taint的更新、删除事件
1 | pkg/controller/nodelifecycle/scheduler/taint_manager.go:419 |
后续就是依次处理每个节点的Pod
1 | 如果节点的pod的toleration 不满足节点的taint,则取消对pod的定时事件处理,立即将该pod删除,将pod 加入到删除队列 |
1 | 经过查看time——worker的代码,可以解释上述问题,在执行tc.taintEvictionQueue.AddWork 时,会调用CreateWorker,当fireAt 时间小于createAt 时间时,直接触发删除pod 的操作 |
taintEvictionQueue的处理函数:尝试删除pod,删除失败时,尝试5次,每一次sleep 0.01秒
1 | func deletePodHandler(c clientset.Interface, emitEventFunc func(types.NamespacedName)) func(args *WorkArgs) error { |
timedworkerqueue,在执行workerfun(deletePodHandler)后,就直接把worker在队列中删除,不再执行了,删除失败了如何处理呢?等待后续的处理?
1 | func (q *TimedWorkerQueue) getWrappedWorkerFunc(key string) func(args *WorkArgs) error { |
频繁给节点增加污点删除污点的问题
现象
将一个Statefulset的Pod运行在node2,此时给节点打上污点,taint_manager 会驱逐节点的Pod
1 | kubectl cordon node2 |
再移除节点的污点,此时 该pod会重新运行在node2
1 | kubectl uncordon node2 |
给节点增加污点,Statefulset的Pod被删除,再执行移除节点污点的操作,POd正常运行在该节点,此时间隔比较短的实际执行增加污点的操作,此时会发现等待很长时间,Statefulset的Pod也不会被删除,如下所示
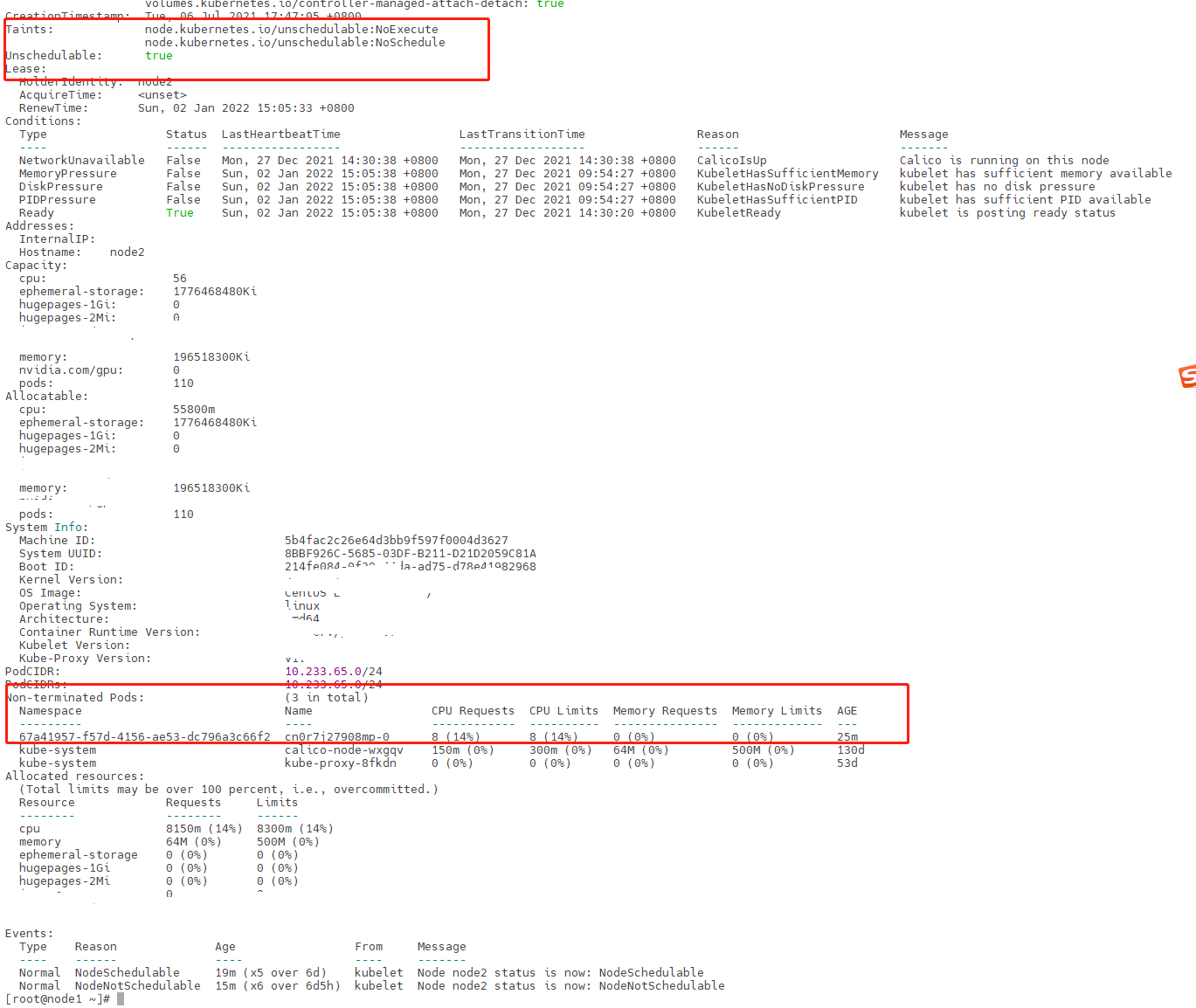
观察日志可以看到,当清楚节点污点时,controller-manager会将驱逐队列清空
Cancelling TimedWorkerQueue item…

日志中是执行了两边增加污点和删除污点的操作,删除污点时正常情况会有两条
1
timed_workers.go:129] Cancelling TimedWorkerQueue item 67a41957-f57d-4156-ae53-dc796a3c66f2/cn0r7j27908mp-0
此时只有1条,证明还没有删除 67a41957-f57d-4156-ae53-dc796a3c66f2/cn0r7j27908mp-0 对应的key,但是此时收到了增加污点的操作,由于队列中仍然还存在这个key,则没有执行CreateWorker的操作,导致Pod 一直存在,参考以下代码和日志
1 | // AddWork adds a work to the WorkerQueue which will be executed not earlier than `fireAt`. |
我们可以看到日志有以下信息
1 | I0102 07:42:44.106288 1 taint_manager.go:440] Updating known taints on node node2: [{node.kubernetes.io/unschedulable NoExecute <nil>}] |
原因分析
- 执行操作间隔时间太短,以及taint—manager有多个worker处理该消息
1 | for i := 0; i < UpdateWorkerSize; i++ { |
- taint删除pod 成功时,taint 队列也未清除该pod名称
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15func (q *TimedWorkerQueue) getWrappedWorkerFunc(key string) func(args *WorkArgs) error {
return func(args *WorkArgs) error {
err := q.workFunc(args)
q.Lock()
defer q.Unlock()
if err == nil {
// To avoid duplicated calls we keep the key in the queue, to prevent
// subsequent additions.
q.workers[key] = nil
} else {
delete(q.workers, key)
}
return err
}
}
- 进行删除Pod时,进行尝试删除,删除失败后只是返回error,将该pod从taint队列中移除,等待下一次处理。但是如果没有下一次的事件触发,Pod应该无法被删除了(只是猜测)