基于GPUDirect 技术,可以使网卡驱动,存储驱动直接从GPU 内存中读取和写入数据,不再需要经过主机CPU、主机内存,减少数据拷贝,GPUDirect技术包括
- GPUDirect Storage
- GPUDirect Remote Direct Memory Access (RDMA)
- GPUDirect Peer to Peer (P2P)
- GPUDirect Video
GPUDirect Storage
1 | NVIDIA® GPUDirect® Storage (GDS) is the newest addition to the GPUDirect family. GDS enables a direct data path for direct memory access (DMA) transfers between GPU memory and storage, which avoids a bounce buffer through the CPU. This direct path increases system bandwidth and decreases the latency and utilization load on the CPU. |
在本地存储和远端存储搭建一条直接的数据通道,(Nvme,NVME over Fabric, GPU memory),避免基于CPU 内存的拷贝,可以在网卡或者存储 开启 DMA(Direct Memory Access),如下图所示:
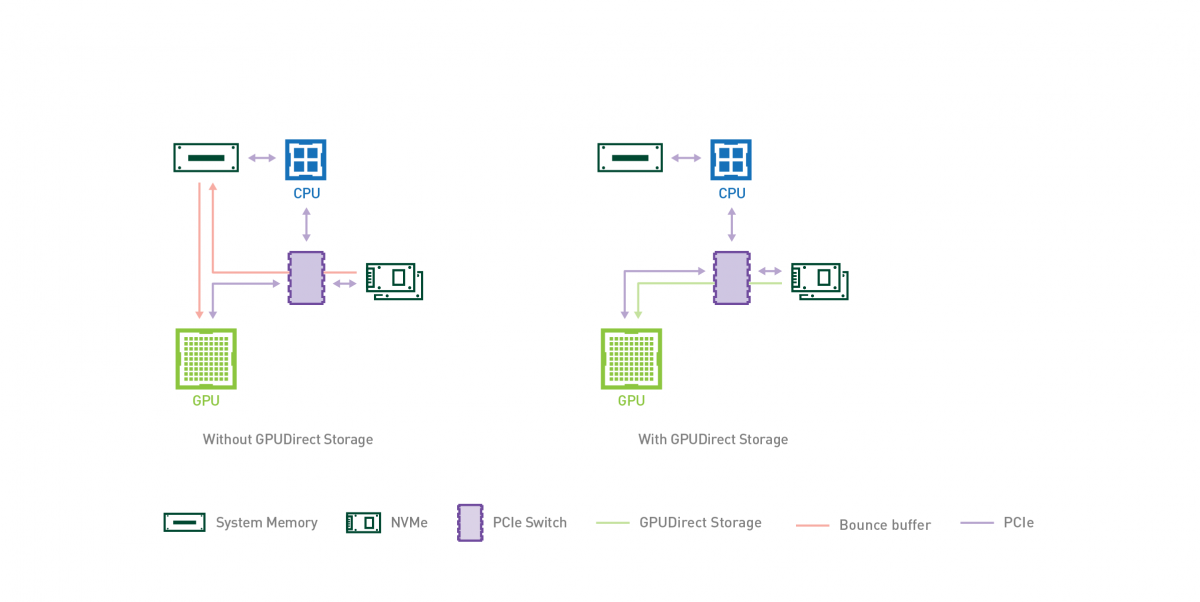
使用GPUDirect Storage 需要安装单独的软件,查看Nvidia 官网,目前支持Ubuntu 操作系统,目前GPUDirect Storage 还是一个比较新的技术

GPUDirect RDMA
更多详细的内容参考这里
用于节点间的GPU 之间直接通信,避免了依赖CPU和主机内存的复制,可以提高10倍的性能,GPUDirect RDMA 属于CUDA的一部分,需要下载第三方的Network 驱动来支持 GPUDirect RDMA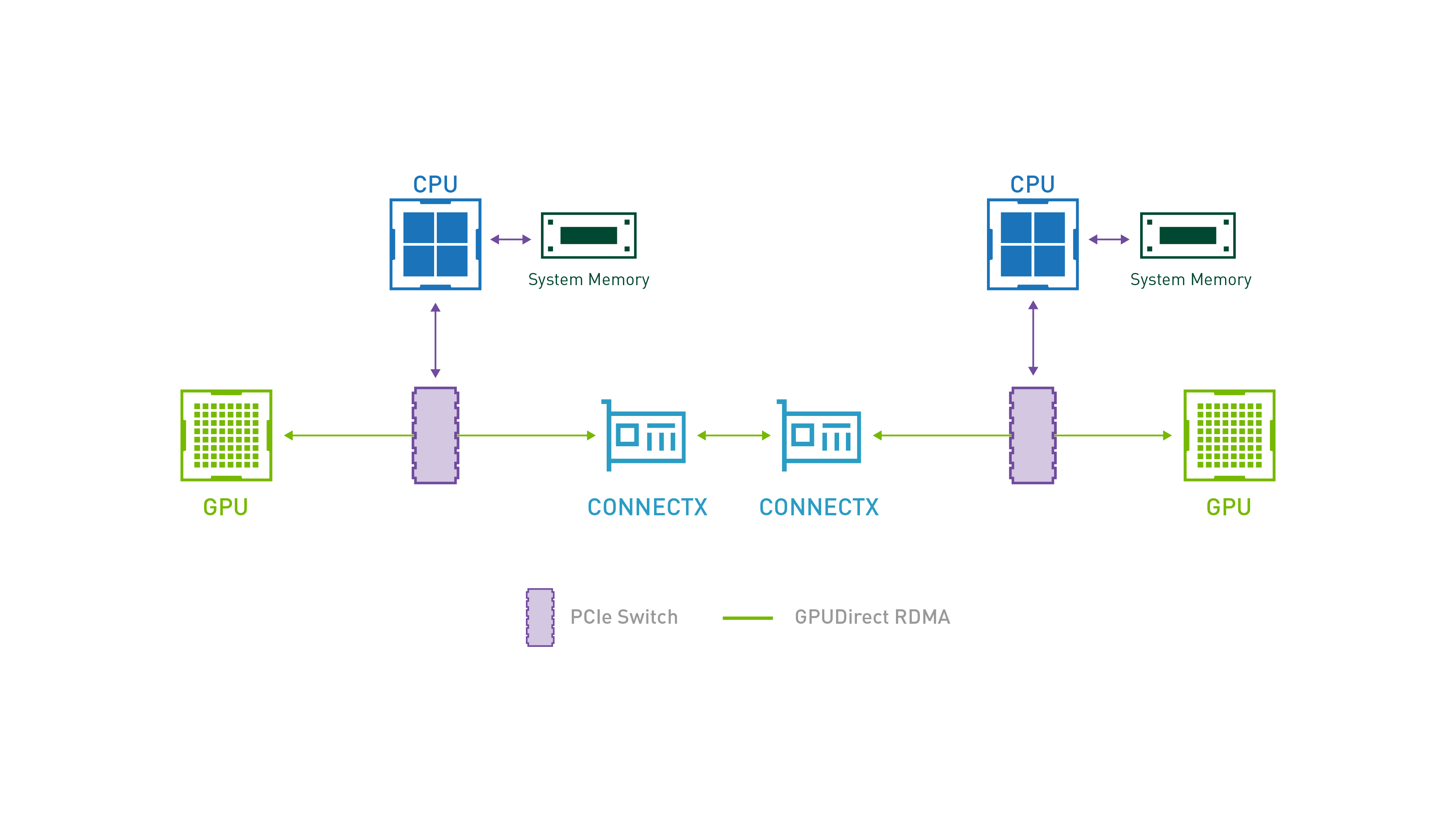
GPU Direct leverages PeerDirect RDMA and PeerDirect ASYNC™ capabilities of the Mellanox network adapters. 对于HCA卡,需要安装nvidia-peer-memory服务
在单个节点上,如果需要启用GPUDirect RDMA功能,需要保证GPU与第三设备属于同一个PCI Express,我们在外部看来就是必须属于一个NUMA 组
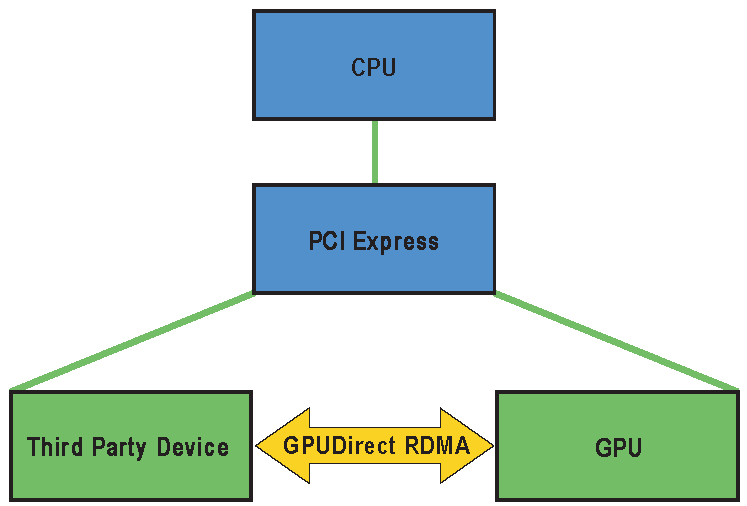
GPUDirect RDMA 如何工作?
当设置两个Peer(不通节点的两个GPU)间使用 GPU Direct时,在PCI Express设备的角度看,所有的物理地址相同。在此物理地址空间内是称为PCI BAR的线性窗口。 每个设备最多具有六个BAR寄存器,因此它最多可以具有六个活动的32位BAR区域。 64位BAR占用两个BAR寄存器。 PCI Express设备以对等设备的BAR地址发布到系统内存的相同方式来进行读写操作。传统上,使用CPU的MMU作为内存映射的I / O(MMIO)地址,将BAR窗口之类的资源映射到用户或内核地址空间。 但是,由于当前的操作系统没有足够的机制来在驱动程序之间交换MMIO区域,因此NVIDIA内核驱动程序会导出功能以执行必要的地址转换和映射。
通常的 DMA 转换(Standard DMA Transfer)

GPUDirect RDMA Transfers

支持的系统 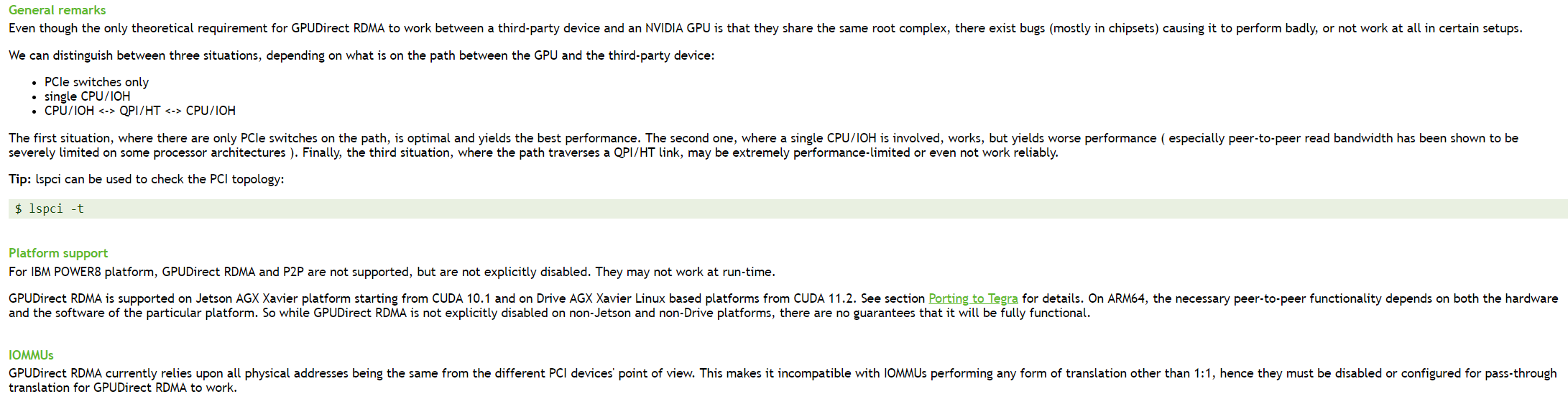
对服务器配置有一定的要求才能达到最优性能,(终于明白为啥最新的A100服务器都需要有多个IB卡了,如果一台GPU服务器上有8张GPU卡,可能会存在8张Infiniband卡)

什么是PCI BAR Size