eBPF的介绍
eBPF源于早年间的成型于 BSD 之上的传统技术 BPF(Berkeley Packet Filter)。BPF 的全称是 Berkeley Packet Filter,顾名思义,这是一个用于过滤(filter)网络报文(packet)的架构。BPF 是在 1997 年首次被引入 Linux 的,Linux 内核中的报文过滤机制其实是有自己的名字的:Linux Socket Filter,简称 LSF。从 3.15 开始,一个套源于 BPF 的全新设计开始,在3.17被添置到了 kernel/bpf 下。全新设计最终被命名为了 extended BPF(eBPF);为了后向兼容,传统的 BPF 仍被保留了下来,并被重命名为 classical BPF(cBPF)。相对于 cBPF,eBPF 带来的改变可谓是革命性的:一方面,它已经为内核追踪(Kernel Tracing)、应用性能调优/监控、流控(Traffic Control)等领域带来了激动人心的变革;另一方面,在接口的设计以及易用性上,eBPF 也有了较大的改进。
cBPF 所覆盖的功能范围很简单,就是网络监控和 seccomp 两块,数据接口设计的粗放;而 eBPF 的利用范围要广的多,性能调优、内核监控、流量控制什么的,数据接口的多样性设计。
使用eBPF可以做什么?
一个eBPF程序会附加到指定的内核代码路径中,当执行该代码路径时,会执行对应的eBPF程序。鉴于它的起源,eBPF特别适合编写网络程序,将该网络程序附加到网络socket,进行流量过滤,流量分类以及执行网络分类器的动作。eBPF程序甚至可以修改一个已建链的网络socket的配置。XDP工程会在网络栈的底层运行eBPF程序,高性能地进行处理接收到的报文。从下图可以看到eBPF支持的功能,eBPF是一项革命性的技术,可以在Linux内核中运行沙盒程序,而无需更改内核源代码或加载内核模块。通过使Linux内核可编程,基础架构软件可以利用现有的层,从而使它们更加智能和功能丰富,而无需继续为系统增加额外的复杂性层。·
上个图,目前没有看明白
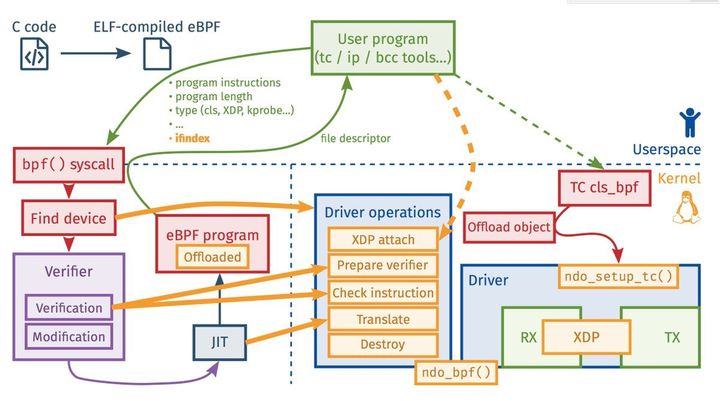
eBFP程序
在很多情况下,不是直接使用eBPF,而是通过Cilium,bcc或bpftrace等项目间接使用eBPF,这些项目在eBPF之上提供了抽象,并且不需要直接编写程序,而是提供了指定基于意图的定义的功能,然后使用eBPF实施。如果不存在更高级别的抽象,则需要直接编写程序。 Linux内核希望eBPF程序以字节码的形式加载。虽然当然可以直接编写字节码,但更常见的开发实践是利用LLVM之类的编译器套件将伪C代码编译为eBPF字节码。
eBPF调用关系(运行架构)
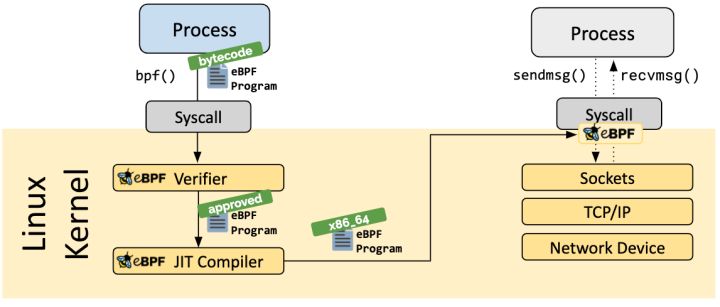
eBPF 项目
bpftrace项目,项目地址
bpftrace是Linux eBPF的高级跟踪语言。它的语言受awk和C以及DTrace和SystemTap等以前的跟踪程序的启发。 bpftrace使用LLVM作为后端将脚本编译为eBPF字节码,并利用BCC作为与Linux eBPF子系统以及现有Linux跟踪功能和连接点进行交互的库。
bcc项目,项目地址
现在可以用 C 来实现 BPF,但编译出来的却仍然是 ELF 文件,开发者需要手动析出真正可以注入内核的代码。这工作有些麻烦,于是就有人设计了 BPF Compiler Collection(BCC),BCC 是一个 python 库,但是其中有很大一部分的实现是基于 C 和 C++的,python实现了对 BCC 应用层接口的封装。使用 BCC 进行 BPF 的开发仍然需要开发者自行利用 C 来设计 BPF 程序——但也仅此而已,余下的工作,包括编译、解析 ELF、加载 BPF 代码块以及创建 map 等等基本可以由 BCC 一力承担,无需多劳开发者费心
Cilium项目,项目地址
Cilium是一个开源项目,提供基于eBPF的联网,安全性和可观察性。它是从头开始专门设计的,旨在将eBPF的优势带入Kubernetes的世界,并满足容器工作负载的新可伸缩性,安全性和可见性要求。