docker hook 的 doPrestart
https://github.com/opencontainers/runtime-spec
1 | Prestart |
Hook:
可以通过与外部应用程序挂钩来扩展容器的生命周期,从而扩展OCI兼容运行时的功能。用例示例包括复杂的网络配置,垃圾信息搜集等
nvidia-container-toolkit 项目:
新版本的nvidia-docker增加了这个项目,主要是用来实现hook函数,并将GPU相关的参数传递给nvidia-container-cli 进行容器的GPU配置,具体的参数如下所示,在创建、重启容器时,都会执行这样的操作
/usr/bin/nvidia-container-cli –load-kmods –debug=/var/log/nvidia-container-toolkit.log configure –ldconfig=@/sbin/ldconfig –device=all –compute –utility –pid=78717 /var/lib/docker/overlay2/6ac97e95475e9df0f32f7e2f7251ca053651c62292d1a5127c71d33e55904d2b/merged
1 |
|
从环境变量获取GPU 信息,先查询envSwarmGPU,再查询envVars,如果都未设置,则获取镜像中的设置
1 | func getDevicesFromEnvvar(env map[string]string, legacyImage bool) *string { |
nvidia-contaienr-runtime 项目
对接OCI runtime,将hook函数注入
该项目会将nvidia-container-toolkit中的preStart函数作为hook加入到runtime
1 | func addNVIDIAHook(spec *specs.Spec) error { |
项目libnvidia-container 项目
nvidia-docker 的核心项目,用于将GPU驱动、相关的so库,容器可见的GPU 挂载到容器内,该项目中的 cli 相关的代码是用来使用封装nvidia-container-cli 客户端操作,项目libcontainer-toolkit 项目会使用这个cli工具进行配置。
挂载GPU驱动相关
1 | configure_command(){ |
1 | int |
调试
在节点安装完docker、nvidia-docker相关软件后,可以通过修改/etc/nvidia-container-runtime/config.toml,nvidia-container-toolkit的debug日志,如下所示
1 | disable-require = false |
我们通过命令行 运行一个使用GPU卡的容器,可以在/var/log/nvidia-container-toolkit.log 看到以下日志,虽然比较长,但是详细的看到挂载过程
1 | docker run -it --env NVIDIA_VISIBLE_DEVICES=GPU-2fb041ff-6df3-4d00-772d-efb3139a17a1 tensorflow:1.14-cuda10-py36 bash |
具体的日志信息:
1 |
|
重点是这一步 挂载某个GPU
I1222 07:23:34.043137 78755 nvc_mount.c:412] mounting /proc/driver/nvidia/gpus/0000:3b:00.0 at /var/lib/docker/overlay2/6ac97e95475e9df0f32f7e2f7251ca053651c62292d1a5127c71d33e55904d2b/merged/proc/driver/nvidia/gpus/0000:3b:00.0I1222 07:23:34.043225 78755 nvc_mount.c:499] whitelisting device node 195:0
使用的是这个函数
1 | static char * |
proc 文件系统
Linux系统上的/proc目录是一种文件系统,即proc文件系统。与其它常见的文件系统不同的是,/proc是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,用户可以通过这些文件查看有关系统硬件及当前正在运行进程的信息,甚至可以通过更改其中某些文件来改变内核的运行状态。
基于/proc文件系统如上所述的特殊性,其内的文件也常被称作虚拟文件,并具有一些独特的特点。例如,其中有些文件虽然使用查看命令查看时会返回大量信息,但文件本身的大小却会显示为0字节。此外,这些特殊文件中大多数文件的时间及日期属性通常为当前系统时间和日期,这跟它们随时会被刷新(存储于RAM中)有关。
为了查看及使用上的方便,这些文件通常会按照相关性进行分类存储于不同的目录甚至子目录中,如/proc/scsi目录中存储的就是当前系统上所有SCSI设备的相关信息,/proc/N中存储的则是系统当前正在运行的进程的相关信息,其中N为正在运行的进程(可以想象得到,在某进程结束后其相关目录则会消失)。
大多数虚拟文件可以使用文件查看命令如cat、more或者less进行查看,有些文件信息表述的内容可以一目了然,但也有文件的信息却不怎么具有可读性。不过,这些可读性较差的文件在使用一些命令如apm、free、lspci或top查看时却可以有着不错的表现。
proc 文件系统原理
proc文件系统是一个伪文件系统,它只存在于内存中,不在外存存储。proc提供了访问系统内核信息的接口。用户和应用程序可以通过proc访问系统信息。用户和应用程序可以通过proc改变内核的某些参数。由于进程等系统信息是动态改变的,所以proc系统动态从系统内核读出所需信息,并提交给读取它的用户和应用程序。
是否可以动态修改这个文件系统呢?
三个项目的关系
包含三个项目
libnvidia-container项目(核心项目,挂载GPU驱动)、nvidia-container-runtime 项目、nvidia-container-toolkit项目
其中 nvidia-container-toolkit 和libnvidia-container 两个项目时必须安装的,对于nvidia-container-runtime 只是为了方便docker run 直接使用,增加hook 函数使用
nvidia-container-runtime 为 构造OCI 的hook,hook的具体实现为nvidia-container-toolkit项目,nvidia-container-toolkit项目会最终调用libnvidia-container项目的cli进行具体的配置
三个项目的调用顺序
docker runc -> nvidia-container-runtime-> nvidia-container-toolkit ->libnvidia-container
Command line 创建挂载GPU的容器
1 | # Setup a new set of namespaces |
尝试在不同的shell 终端挂载不同的GPU,但是都是只能显示一个GPU
在同样的rootfs 目录,执行挂载主机的0号GPU卡,如下图所示,此时只能查看到一张卡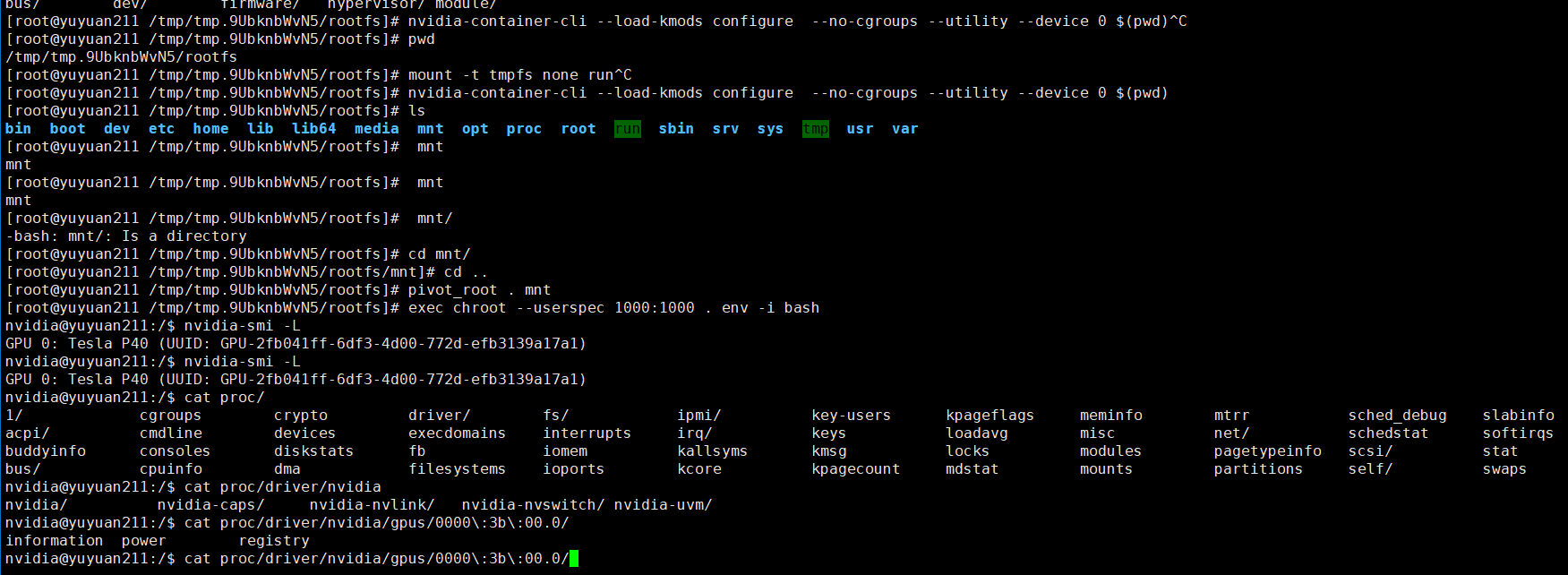
然后在同样的rootfs目录,执行挂载主机的1号GPU卡,如下图所示,此时仍然只能查看到一张卡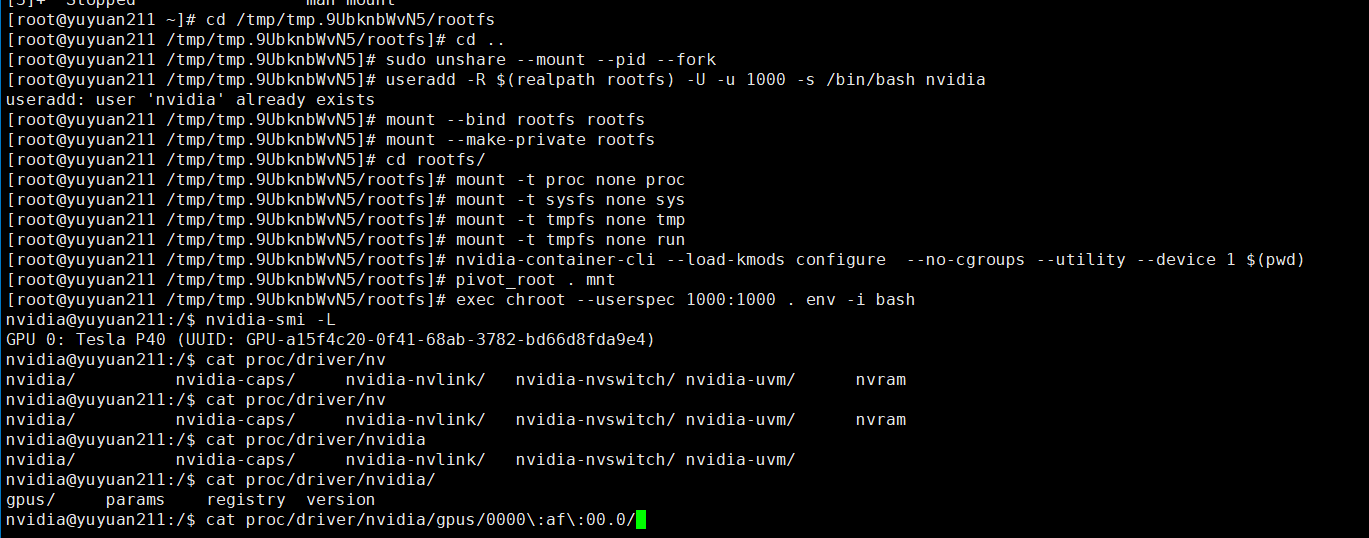
这里的proc 文件系统是关键,执行nvidia-container-cli 在proc 文件系统内就只能查看到指定的GPU 卡了,只能对运行态容器的proc 进行处理.(proc 文件系统是内核提供的映射文件),新挂载的是无法获取到 运行态容器的proc信息